第1天:选择什么样的DOCTYPE
作者:阿捷
前言
大家好!这个系列文章是按阿捷自己制作这个站点的过程编写的。之前阿捷也一直没有制作过一个真正符合web标准的网站。现在边参考国外资料边制作,同时把过程中的心得和经验记录下来,希望对大家有点帮助。好了,让我们开始吧
第一天
开始制作符合标准的站点,第一件事情就是声明符合自己需要的DOCTYPE。
查看本站首页原代码,可以看到第一行就是:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
打开一些符合标准的站点,例如著名web设计软件开发商Macromedia,设计大师Zeldman的个人网站,会发现同样的代码。而另一些符合标准的站点(例如k10k.net)的代码则如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
那么这些代码有什么含义?一定要放置吗?
什么是DOCTYPE
上面这些代码我们称做DOCTYPE声明。DOCTYPE是document type(文档类型)的简写,用来说明你用的XHTML或者HTML是什么版本。
其中的DTD(例如上例中的xhtml1-transitional.dtd)叫文档类型定义,里面包含了文档的规则,浏览器就根据你定义的DTD来解释你页面的标识,并展现出来。
要建立符合标准的网页,DOCTYPE声明是必不可少的关键组成部分;除非你的XHTML确定了一个正确的DOCTYPE,否则你的标识和CSS都不会生效。
XHTML 1.0 提供了三种DTD声明可供选择:
- 过渡的(Transitional):要求非常宽松的DTD,它允许你继续使用HTML4.01的标识(但是要符合xhtml的写法)。完整代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
- 严格的(Strict):要求严格的DTD,你不能使用任何表现层的标识和属性,例如<br>。完整代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
- 框架的(Frameset):专门针对框架页面设计使用的DTD,如果你的页面中包含有框架,需要采用这种DTD。完整代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
我们选择什么样的DOCTYPE
理想情况当然是严格的DTD,但对于我们大多数刚接触web标准的设计师来说,过渡的DTD(XHTML 1.0 Transitional)是目前理想选择(包括本站,使用的也是过渡型DTD)。因为这种DTD还允许我们使用表现层的标识、元素和属性,也比较容易通过W3C的代码校验。
注:上面说的"表现层的标识、属性"是指那些纯粹用来控制表现的tag,例如用于排版的表格、背景颜色标识等。在XHTML中标识是用来表示结构的,而不是用来实现表现形式,我们过渡的目的是最终实现数据和表现相分离。
打个比方:人体模特换衣服。模特就好比数据,衣服则是表现形式,模特和衣服是分离的,这样你就可以随意换衣服。而原来HTML4中,数据和表现是混杂在一起的,要一次性换个表现形式非常困难。呵呵,有点抽象了,这个概念需要我们在应用过程中逐步领会。
补充
DOCTYPE声明必须放在每一个XHTML文档最顶部,在所有代码和标识之上。
第2天:什么是名字空间
DOCTYPE声明好以后,接下来的代码是:
<html xmlns="http://www.w3.org/1999/xhtml" lang="gb2312">
通常我们HTML4.0的代码只是<html>,这里的"xmlns"是什么呢?
这个"xmlns"是XHTML namespace的缩写,叫做"名字空间"声明。名字空间是什么作用呢?阿捷自己的理解是:
由于xml允许你自己定义自己的标识,你定义的标识和其他人定义的标识有可能相同,但表示不同的意义。当文件交换或者共享的时候就容易产生错误。为了避免这种错误发生,XML采用名字空间声明,允许你通过一个网址指向来识别你的标识。例如:
小王和小李都定义了一个<book>标识,如果小王的名字空间是"http://www.xiaowang.com",小李的名字空间是"http://www.xiaoli.com",那么当两个文档交换数据时,也不会混淆<book>标识,因为它属于不同的名字空间。
更通俗的解释是:名字空间就是给文档做一个标记,告诉别人,这个文档是属于谁的。只不过这个"谁"用了一个网址来代替。
XHTML是HTML向XML过渡的标识语言,它需要符合XML文档规则,因此也需要定义名字空间。又因为XHTML1.0不能自定义标识,所以它的名字空间都相同,就是"http://www.w3.org/1999/xhtml"。如果你还不太理解也不要紧,目前阶段我们只要照抄代码就可以了。
后面的lang="gb2312",指定你的文档用简体中文。
第3天:定义语言编码
第三步是定义你的语言编码,类似这样:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
为了被浏览器正确解释和通过W3C代码校验,所有的XHTML文档都必须声明它们所使用的编码语言,我们一般使用gb2312(简体中文),制作多国语言页面也有可能用Unicode、ISO-8859-1等,根据你的需要定义。
通常这样定义就可以了。但是要补充说明的是,XML文档并不是这样定义语言编码的,XML的定义方式如下:
<?xml version="1.0" encoding="gb2312"?>
你在Macromedia.com的首页代码第一行就可以看见类似的语句,这也是W3C推荐使用的定义方法。那为什么我们不直接采用这种方法呢?原因是一些浏览器对标准的支持不完善,不能正确理解这样的定义方法,比如IE6/windows。所以在目前过渡方案下,我们依然推荐使用meta方式。当然,你可以两种方法都写。
看本站源代码,你会发现语言编码定义的地方还多一句:
<meta http-equiv="Content-Language" content="gb2312" />
这是针对老版本浏览器写的,以保证各种浏览器都能正确解释页面。
注意:在上面声明语句的最后,你看到有一个斜杠"/",这和我们以前的HTML4.0的代码写法不同。原因是XHTML语法规则要求所有的标识都必须有开始和结束。例如<body>和</body>、<p>和</p>等,对于不成对的标识,要求在标识最后加一个空格,然后跟一个"/"。例如<br>写成<br />、<img>写成<img />,加空格的原因是避免代码连在一起浏览器不识别。
第4天:调用样式表
用web标准设计网站,过渡的方法主要是采用XHTML+CSS,css样式表是必不可少的。这就要求所有网页设计师必须熟练掌握CSS,如果你以前不常用,那么现在就开始学习吧。要制作符合web标准的网站,不懂CSS是设计不出漂亮的页面的。
事实上,所有表现的地方都需要用CSS来实现。我们以前都习惯用table来定位和布局,现在要改用DIV来定位和布局。这是思维方式的变化,一开始有些不习惯。呵呵,任何变革都会有阻力的,为了享受标准带来的"益处",放弃一些老的传统做法是值得的。
外部调用样式表
在以前,我们通常采用2种方法使用样式表:
- 页面内嵌法:就是将样式表直接写在页面代码的head区。类似这样:
<style type="text/css"> <!– body { background : white ; color : black ; } –> </style>
- 外部调用法:将样式表写在一个独立的.css文件中,然后在页面head区用类似以下代码调用。
<link rel="stylesheet" rev="stylesheet" href="css/style.css" type="text/css" media="all" />
在符合web标准的设计中,我们使用外部调用法,好处不言而喻,你可以不修改页面只修改.css文件而改变页面的样式。如果所有页面都调用同一个样式表文件,那么改一个样式表文件,可以改变所有文件的样式。
双表法调用样式表
查看某些符合标准站点的原代码,你可能看到,在调用样式表的地方有如下2句:
<link rel="stylesheet" rev="stylesheet" href="css/style.css" type="text/css" media="all" /> <style type="text/css" media="all">@import url( css/style01.css );</style>
为什么要写两次呢?
实际上一般情况下用外联法调用(就是第一句)就足够了。我这里使用双表调用只是一种示例。其中的"@import"命令用于输入样式表。而"@import"命令在netscape 4.0版本浏览器是无效的。也就是说,当你希望某些效果在netscape 4.0浏览器中隐藏,在4.0以上或其它浏览器中又显示的时候,你可以采用"@import"命令方法调用样式表。
第5天:head区的其他设置
这些技巧主要讲meta标签设置的,其实与符合web标准关系不大,只要注意在最后加"/"关闭标签就可以,但是既然是入门教程,就写得详细一点吧。
收藏夹小图标
如果你将本站加入收藏夹,可以看到在收藏夹网址之前的IE图标变成了本站特别的图标 。要实现这样效果很简单,首先制作一个16×16的icon图标,命名为favicon.ico,放在根目录下。然后将下面的代码嵌入head区:
。要实现这样效果很简单,首先制作一个16×16的icon图标,命名为favicon.ico,放在根目录下。然后将下面的代码嵌入head区:
<link rel="icon" href="/favicon.ico" type="image/x-icon" />
<link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" />
为搜索引擎准备的内容
代码如下,替换成你自己站点的内容就可以:
<meta content="all" name="robots" />
<meta name="author" content="ajie@netease.com,阿捷" />
<meta name="Copyright" content="www.w3cn.org,自由版权,任意转载" />
<meta name="description" content="新网页设计师。web标准的教程站点,推动web标准在中国的应用" />
<meta content="designing, with, web, standards, xhtml, css, graphic, design, layout, usability, ccessibility, w3c, w3, w3cn, ajie" name="keywords" />
先介绍这么多。补充说明,前面花了5节都是讲head区的代码,实际页面内容还一字未提,呵呵,不要急,其实head区是非常重要的,看一个页面的head的代码就可以知道设计师是否够专业。
第6天:XHTML代码规范
在开始正式内容制作之前,我们必须先了解一下web标准有关代码的规范。了解这些规范可以帮助你少走弯路,尽快通过代码校验。
1.所有的标记都必须要有一个相应的结束标记
以前在HTML中,你可以打开许多标签,例如<p>和<li>而不一定写对应的</p>和</li>来关闭它们。但在XHTML中这是不合法的。XHTML要求有严谨的结构,所有标签必须关闭。如果是单独不成对的标签,在标签最后加一个"/"来关闭它。例如:
<br /><img height="80" alt="网页设计师" src="../images/logo_w3cn_200x80.gif" width="200" />
2.所有标签的元素和属性的名字都必须使用小写
与HTML不一样,XHTML对大小写是敏感的,<title>和<TITLE>是不同的标签。XHTML要求所有的标签和属性的名字都必须使用小写。例如:<BODY>必须写成<body> 。大小写夹杂也是不被认可的,通常dreamweaver自动生成的属性名字"onMouseOver"也必须修改成"onmouseover"。
3.所有的XML标记都必须合理嵌套
同样因为XHTML要求有严谨的结构,因此所有的嵌套都必须按顺序,以前我们这样写的代码:
<p><b></p>/b>
必须修改为:
<p><b></b>/p>
就是说,一层一层的嵌套必须是严格对称。
4.所有的属性必须用引号""括起来
在HTML中,你可以不需要给属性值加引号,但是在XHTML中,它们必须被加引号。例如:
<height=80>
必须修改为:
<height="80">
特殊情况,你需要在属性值里使用双引号,你可以用",单引号可以使用',例如:
<alt="say'hello'">
5.把所有<和&特殊符号用编码表示
- 任何小于号(<),不是标签的一部分,都必须被编码为& l t ;
- 任何大于号(>),不是标签的一部分,都必须被编码为& g t ;
- 任何与号(&),不是实体的一部分的,都必须被编码为& a m p;
注:以上字符之间无空格。
6.给所有属性赋一个值
XHTML规定所有属性都必须有一个值,没有值的就重复本身。例如:
<td nowrap> <input type="checkbox" name="shirt" value="medium" checked>
必须修改为:
<td nowrap="nowrap"> <input type="checkbox" name="shirt" value="medium" checked="checked">
7.不要在注释内容中使“–”
“–”只能发生在XHTML注释的开头和结束,也就是说,在内容中它们不再有效。例如下面的代码是无效的:
<!–这里是注释———–这里是注释–>
用等号或者空格替换内部的虚线。
<!–这里是注释============这里是注释–>
以上这些规范有的看上去比较奇怪,但这一切都是为了使我们的代码有一个统一、唯一的标准,便于以后的数据再利用。
第7天:CSS入门
在了解XHTML代码规范后,我们就要进行CSS布局。首先先介绍一些CSS的入门知识。如果你已经很熟悉了,可以跳过这一节,直接进入下一节。
CSS是Cascading Style Sheets(层叠样式表)的缩写。是一种对web文档添加样式的简单机制,属于表现层的布局语言。
1.基本语法规范
分析一个典型CSS的语句:
p {COLOR:#FF0000;BACKGROUND:#FFFFFF}
- 其中"p"我们称为"选择器"(selectors),指明我们要给"p"定义样式;
- 样式声明写在一对大括号"{}"中;
- COLOR和BACKGROUND称为"属性"(property),不同属性之间用分号";"分隔;
- "#FF0000"和"#FFFFFF"是属性的值(value)。
2.颜色值
颜色值可以用RGB值写,例如:color : rgb(255,0,0),也可以用十六进制写,就象上面例子color:#FF0000。如果十六进制值是成对重复的可以简写,效果一样。例如:#FF0000可以写成#F00。但如果不重复就不可以简写,例如#FC1A1B必须写满六位。
3.定义字体
web标准推荐如下字体定义方法:
body { font-family : "Lucida Grande", Verdana, Lucida, Arial, Helvetica, 宋体,sans-serif; }
- 字体按照所列出的顺序选用。如果用户的计算机含有Lucida Grande字体,文档将被指定为Lucida Grande。没有的话,就被指定为Verdana字体,如果也没有Verdana,就指定为Lucida字体,依此类推,;
- Lucida Grande字体适合Mac OS X;
- Verdana字体适合所有的Windows系统;
- Lucida适合UNIX用户
- "宋体"适合中文简体用户;
- 如果所列出的字体都不能用,则默认的sans-serif字体能保证调用;
4.群选择器
当几个元素样式属性一样时,可以共同调用一个声明,元素之间用逗号分隔,: p, td, li { font-size : 12px ; }
5.派生选择器
可以使用派生选择器给一个元素里的子元素定义样式,例如这样:
li strong { font-style : italic; font-weight : normal;}
就是给li下面的子元素strong定义一个斜体不加粗的样式。
6.id选择器
用CSS布局主要用层"div"来实现,而div的样式通过"id选择器"来定义。例如我们首先定义一个层
<div id="menubar"></div>
然后在样式表里这样定义:
#menubar {MARGIN: 0px;BACKGROUND: #FEFEFE;COLOR: #666;}
其中"menubar"是你自己定义的id名称。注意在前面加"#"号。
id选择器也同样支持派生,例如:
#menubar p { text-align : right; margin-top : 10px; }
这个方法主要用来定义层和那些比较复杂,有多个派生的元素。
6.类别选择器
在CSS里用一个点开头表示类别选择器定义,例如:
.14px {color : #f60 ;font-size:14px ;}
在页面中,用class="类别名"的方法调用:
<span class="14px">14px大小的字体</span>
这个方法比较简单灵活,可以随时根据页面需要新建和删除。
7.定义链接的样式
CSS中用四个伪类来定义链接的样式,分别是:a:link、a:visited、a:hover和a : active,例如:
a:link{font-weight : bold ;text-decoration : none ;color : #c00 ;}
a:visited {font-weight : bold ;text-decoration : none ;color : #c30 ;}
a:hover {font-weight : bold ;text-decoration : underline ;color : #f60 ;}
a:active {font-weight : bold ;text-decoration : none ;color : #F90 ;}
以上语句分别定义了"链接、已访问过的链接、鼠标停在上方时、点下鼠标时"的样式。注意,必须按以上顺序写,否则显示可能和你预想的不一样。记住它们的顺序是“LVHA”。
呵呵,看了这么多,有点头晕吧,实际上CSS的语法规范还有很多,这里列的只是一些常用的,毕竟我们是循序渐进,不可能一口吃成胖子:)
第8天:CSS布局入门
CSS布局与传统表格(table)布局最大的区别在于:原来的定位都是采用表格,通过表格的间距或者用无色透明的GIF图片来控制文布局版块的间距;而现在则采用层(div)来定位,通过层的margin,padding,border等属性来控制版块的间距。
1.定义DIV
分析一个典型的定义div例子:
#sample{ MARGIN: 10px 10px 10px 10px;
PADDING:20px 10px 10px 20px;
BORDER-TOP: #CCC 2px solid;
BORDER-RIGHT: #CCC 2px solid;
BORDER-BOTTOM: #CCC 2px solid;
BORDER-LEFT: #CCC 2px solid;
BACKGROUND: url(images/bg_poem.jpg) #FEFEFE no-repeat right bottom;
COLOR: #666;
TEXT-ALIGN: center;
LINE-HEIGHT: 150%; WIDTH:60%; }
说明如下:
- 层的名称为sample,在页面中用<div id="sample">就可以调用这个样式。
- MARGIN是指层的边框以外留的空白,用于页边距或者与其它层制造一个间距。"10px 10px 10px 10px"分别代表"上右下左"(顺时针方向)四个边距,如果都一样,可以缩写成"MARGIN: 10px;"。如果边距为零,要写成"MARGIN: 0px;"。注意:当值是零时,除了RGB颜色值0%必须跟百分号,其他情况后面可以不跟单位"px"。MARGIN是透明元素,不能定义颜色。
- PADDING是指层的边框到层的内容之间的空白。和margin一样,分别指定上右下左边框到内容的距离。如果都一样,可以缩写成"PADDING:0px"。单独指定左边可以写成"PADDING-LEFT: 0px;"。PADDING是透明元素,不能定义颜色。
- BORDER是指层的边框,"BORDER-RIGHT: #CCC 2px solid;"是定义层的右边框颜色为"#CCC",宽度为"2px",样式为"solid"直线。如果要虚线样式可以用"dotted"。
- BACKGROUND是定义层的背景。分2级定义,先定义图片背景,采用"url(../images/bg_logo.gif)"来指定背景图片路径;其次定义背景色"#FEFEFE"。"no-repeat"指背景图片不需要重复,如果需要横向重复用"repeat-x",纵向重复用"repeat-y",重复铺满整个背景用"repeat"。后面的"right bottom;"是指背景图片从右下角开始。如果没有背景图片可以只定义背景色BACKGROUND: #FEFEFE
- COLOR用于定义字体颜色,上一节已经介绍过。
- TEXT-ALIGN用来定义层中的内容排列方式,center居中,left居左,right居右。
- LINE-HEIGHT定义行高,150%是指高度为标准高度的150%,也可以写作:LINE-HEIGHT:1.5或者LINE-HEIGHT:1.5em,都是一样的意思。
- WIDTH是定义层的宽度,可以采用固定值,例如500px,也可以采用百分比,象这里的"60%"。要注意的是:这个宽度仅仅指你内容的宽度,不包含margin,border和padding。但在有些浏览器中不是这么定义的,需要你多试试。
下面是这个层的实际表现:
这里是演示内容,这里是演示内容,这里是演示内容,这里是演示内容,这里是演示内容,这里是演示内容,这里是演示内容,这里是演示内容,
这里是演示内容,这里是演示内容,
这里是演示内容,这里是演示内容,
这里是演示内容…
我们可以看到边框是2px的灰色,背景图片在右下没有重复,内容距离上和左边框20px,内容居中,一切和预想的一样。hoho,虽然不好看,但它是最基本的,掌握了它,你就已经学会一半的CSS布局技术了。就是这样,不算难吧!(另一半是什么?另一半是层与层之间的定位。我会在后面逐步讲解。)
2.CSS2盒模型
自从1996年CSS1的推出,W3C组织就建议把所有网页上的对像都放在一个盒(box)中,设计师可以通过创建定义来控制这个盒的属性,这些对像包括段落、列表、标题、图片以及层<div>。盒模型主要定义四个区域:内容(content)、边框距(padding)、边界(border)和边距(margin)。上面我们讲的sample层就是一个典型的盒。对于初学者,经常会搞不清楚margin,background-color,background-image,padding,content,border之间的层次、关系和相互影响。这里提供一张盒模型的3D示意图,希望便于你的理解和记忆。
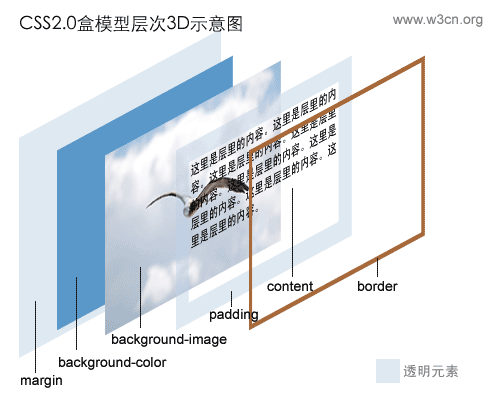
3.辅助图片一律用背景处理
用XHTML+CSS布局,有一个技术一开始让你不习惯,应该说是一种思维方式与传统表格布局不一样,那就是:所有辅助图片都用背景来实现。类似这样:
BACKGROUND: url(images/bg_poem.jpg) #FEFEFE no-repeat right bottom;
尽管可以用<img>直接插在内容中,但这是不推荐的。这里的"辅助图片"是指那些不是作为页面要表达的内容的一部分,而仅仅用于修饰、间隔、提醒的图片。例如:相册中的图片、图片新闻中的图片,上面的3d盒模型图片都属于内容的一部分,它们可以用<img>元素直接插在页面里,而其它的类似logo,标题图片,列表前缀图片都必须采用背景方式或者其他CSS方式显示。
这样做的原因有2点:
- 将表现与结构彻底相分离(参考阅读另一篇文章:《理解表现与结构相分离》),用CSS控制所有的外观表现,便于改版。
- 使页面更具有易用性,更有亲和力。例如:盲人使用屏幕阅读机,用背景技术实现的图片就不会被朗读出来。
第9天:第一个CSS布局实例
接下来开始要真正设计布局了。和传统的方法一样,你首先要在脑海里有大致的轮廓构想,然后用photoshop把它画出来。你可能看到有关web标准的站点大都很朴素,因为web标准更关注结构和内容,实际上它与网页的美观没有根本冲突,你想怎么设计就怎么设计,用传统表格方法实现的布局,用DIV也可以实现。技术有一个成熟的过程,把DIV看成和TABLE一样的工具,如何运用就看你的想象力了。
注:在实际应用过程中,DIV在有些地方的确不如表格方便,比如背景色的定义。但任何事情都有得有失,取舍在于你的价值判断。好,不罗嗦了,我们开始:
1.确定布局
w3cn的最初设计草图如下:
用表格的设计方法的话,一般都是上中下三行布局
。用DIV的话,我考虑使用三列来布局,成为这样
。
2.定义body样式
先定义整个页面的body的样式,代码如下:
body { MARGIN: 0px;
PADDING: 0px;
BACKGROUND: url(../images/bg_logo.gif) #FEFEFE no-repeat right bottom;
FONT-FAMILY: ‘‘‘‘‘‘‘‘Lucida Grande‘‘‘‘‘‘‘‘,‘‘‘‘‘‘‘‘Lucida Sans Unicode‘‘‘‘‘‘‘‘,‘‘‘‘‘‘‘‘宋体‘‘‘‘‘‘‘‘,‘‘‘‘‘‘‘‘新宋体‘‘‘‘‘‘‘‘,arial,verdana,sans-serif;
COLOR: #666;
FONT-SIZE:12px;
LINE-HEIGHT:150%; }
以上代码的作用在上一天的教程有详细说明,大家应该一看就明白。定义了边框边距为0;背景颜色为#FEFEFE,背景图片为bg_logo.gif,图片位于页面右下角,不重复;定义了字体尺寸为12px;字体颜色为#666;行高150%。
3.定义主要的div
初次使用CSS布局,我决定采用固定宽度的三列布局(比自适应分辨率的设计简单,hoho,别说我偷懒,先实现简单的,增加点信心嘛!)。分别定义左中右的宽度为200:300:280,在CSS中如下定义:
/*定义页面左列样式*/
#left{ WIDTH:200px;
MARGIN: 0px;
PADDING: 0px;
BACKGROUND: #CDCDCD;
}
/*定义页面中列样式*/
#middle{ POSITION: absolute;
LEFT:200px;
TOP:0px;
WIDTH:300px;
MARGIN: 0px;
PADDING: 0px;
BACKGROUND: #DADADA;
}
/*定义页面右列样式*/
#right{ POSITION: absolute;
LEFT:500px;
TOP:0px;
WIDTH:280px;
MARGIN: 0px;
PADDING: 0px;
BACKGROUND: #FFF; }
注意:定义中列和右列div我都采用了POSITION: absolute;,然后分别定义了LEFT:200px;TOP:0px;和LEFT:500px;TOP:0px;这是这个布局的关键,我采用了层的绝对定位。定义中间列距离页面左边框200px,距离顶部0px;定义右列距离页面左边框500px,距离顶部0px;。
这时候整个页面的代码是:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="gb2312">
<head>
<title>欢迎进入新《网页设计师》:web标准教程及推广</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<meta http-equiv="Content-Language" content="gb2312" />
<meta content="all" name="robots" />
<meta name="author" content="ajie(at)netease.com,阿捷" />
<meta name="Copyright" content="www.w3cn.org,自由版权,任意转载" />
<meta name="description" content="新网页设计师,web标准的教程站点,推动web标准在中国的应用." />
<meta content="web标准,教程,web, standards, xhtml, css, usability, accessibility" name="keywords" />
<link rel="icon" href="/favicon.ico" type="image/x-icon" />
<link rel="shortcut icon" href="http://www.w3cn.org/favicon.ico" type="image/x-icon" />
<link rel="stylesheet" rev="stylesheet" href="css/style01.css" type="text/css" media="all" />
</head>
<body>
<div id="left">页面左列</div>
<div id="middle">页面中列</div>
<div id="right">页面右列</div>
</body>
</html>
这时候页面的效果仅仅可以看到三个并列的灰色矩形,和一个背景图。但是我希望高度是满屏的,怎么办呢?
4.100%自适应高度?
为了保持三列有同样的高度,我尝试在#left、#middle和#right中设置"height:100%;",但发现完全没有预想的自适应高度效果。经过一番尝试后,我只好给每个div一个绝对高度:"height:1000px;",并且随着内容的增加,需要不断修正这个值。难道没有办法自适应高度了吗?随着阿捷自己学习的深入,发现一个变通的解决办法,实际上根本不需要设置100%,我们已经被table思维禁锢太深了,这个办法在下一节的学习中详细介绍。
第10天:自适应高度
如果我们想在3列布局的最后加一行页脚,放版权之类的信息。就遇到必须对齐3列底部的问题。在table布局中,我们用大表格嵌套小表格的方法,可以很方便对齐三列;而用div布局,三列独立分散,内容高低不同,就很难对齐。其实我们完全可以嵌套div,把三列放进一个DIV中,就做到了底部对齐。下面是实现例子(白色背景框模拟一个页面):
Body
这里是#mainbox { MARGIN: 0px; WIDTH: 580px; BACKGROUND: #FFF; }包含了#menu,#sidebar和#content
这里是#content{ FLOAT: right; MARGIN: 1px 0px 2px 0px; PADDING:0px; WIDTH: 400px; BACKGROUND: #E0EFDE;}
这里是主要内容,根据内容自动适应高度
这里是主要内容,根据内容自动适应高度
这里是主要内容,根据内容自动适应高度
这个例子的页面主要代码如下:
<div id="header"></div>
<div id="mainbox">
<div id="menu"></div>
<div id="sidebar"></div>
<div id="content"></div>
</div>
<div id="footer"></div>
具体样式表都写在相应版块里了。重点在于#mainbox层嵌套了#menu,#sidebar和#content三个层。当#content的内容增加,#content的高度就会增高,同时#mainbox的高度也会撑开,#footer层就自动下移。这样就实现了高度的自适应。
另外值得注意的是:#menu和#content都是浮动在页面右面"FLOAT: right;",#sidebar是浮动在#menu层的左面"FLOAT: left;",这是浮动法定位,还可以采用绝对定位来实现这样的效果。
这个方法存在另一个问题,就是侧列#sidebar的背景无法百分之百。一般的解决办法就是用body的背景色来填充满。(不能使用#mainbox的背景色,因为在Mozilla等浏览器中#mainbox的背景色失效。)
好了,主要的框架已经搭建完毕,剩下的工作只是往里面添砖加瓦。如果你希望尝试其他布局,推荐看看以下文章:
